- Published on
The Last Mile of LLM Inference
- Authors

- Name
- Anirudh Sathiya Narayanan
First we converted the prompt to input tokens. Then, the transformer produced logits. Now you have 50,000 probabilities. How do you choose the next token?
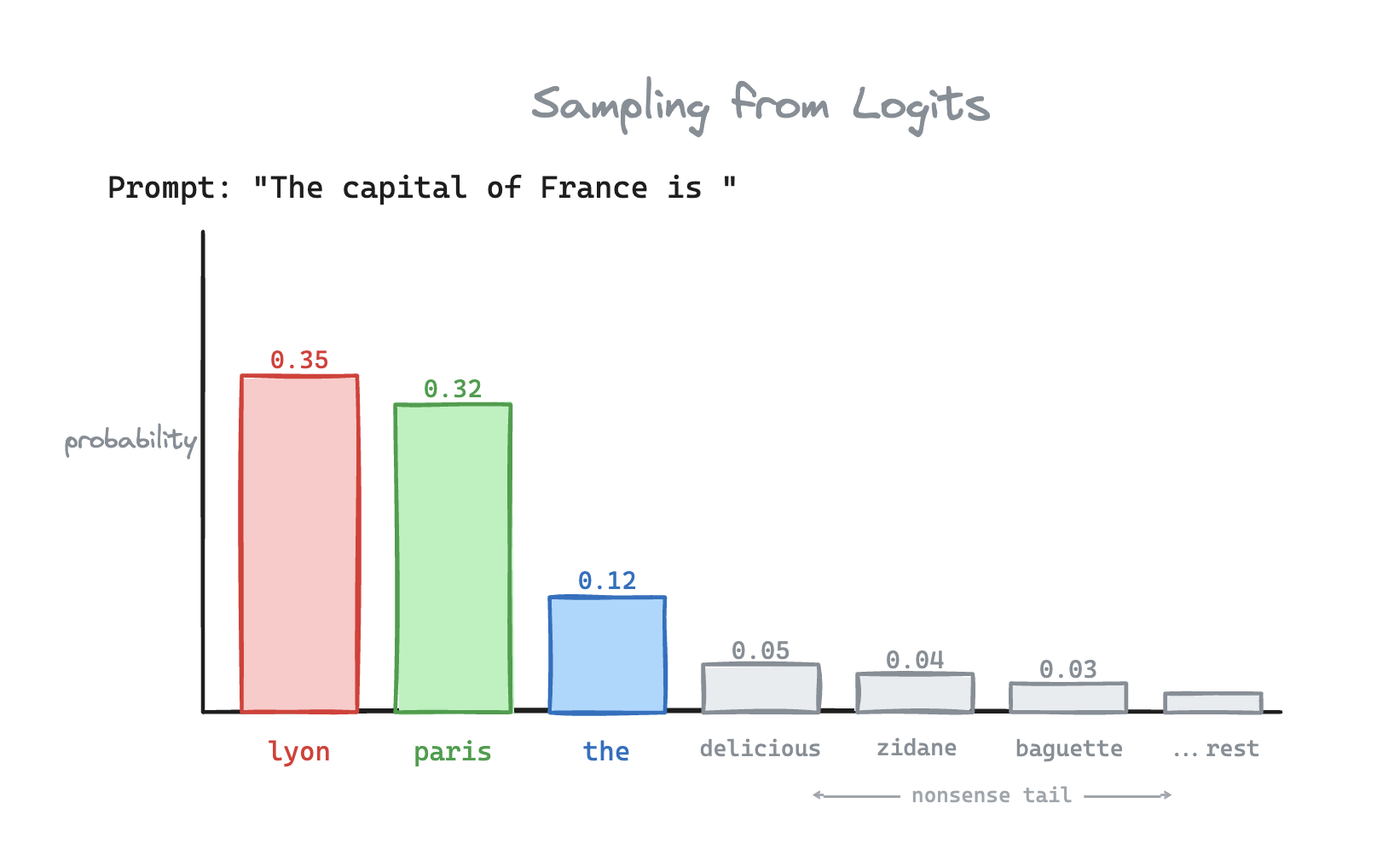
Choose the highest probability!
This is called greedy sampling. Unfortunately for us, Lyon isn't the capital of France. Because the greedy approach is deterministic, the model can get stuck in an infinite loop of repeating the same sentences. Imagine asking ChatGPT
Write me a problem
and getting
The cat sat on the mat. The cat sat on the mat. The cat sat on the mat. The cat sat on the mat...
Congratulations, you've built a very expensive autocomplete.
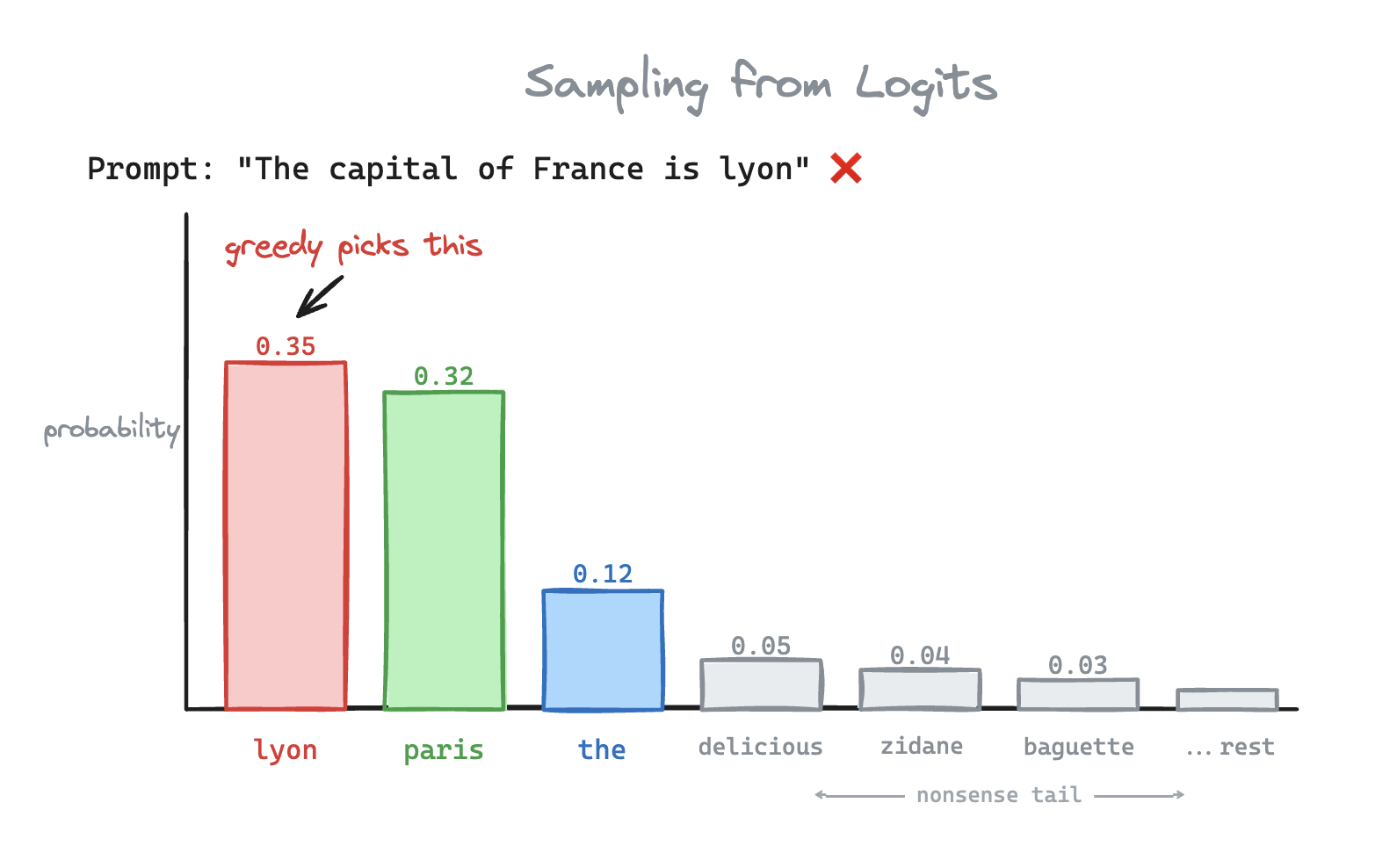
Lets increase the temperature
Okay, so greedy is out. What if we pick each token according to its probability? Paris has a 32% chance, Lyon has a ~35% chance, and remaining tokens have a 33% chance.
This is called sampling. But "Paris" still has the same odds as the other tokens { "the", "delicious", "zidane", "baguette" ... } combined.
Let's add a knob. AKA temperature
Here, the the logit and is the temperature. We divide every logit by the temperature value.
Then re-apply softmax, which normalizes the probability distribution to add up to 1.
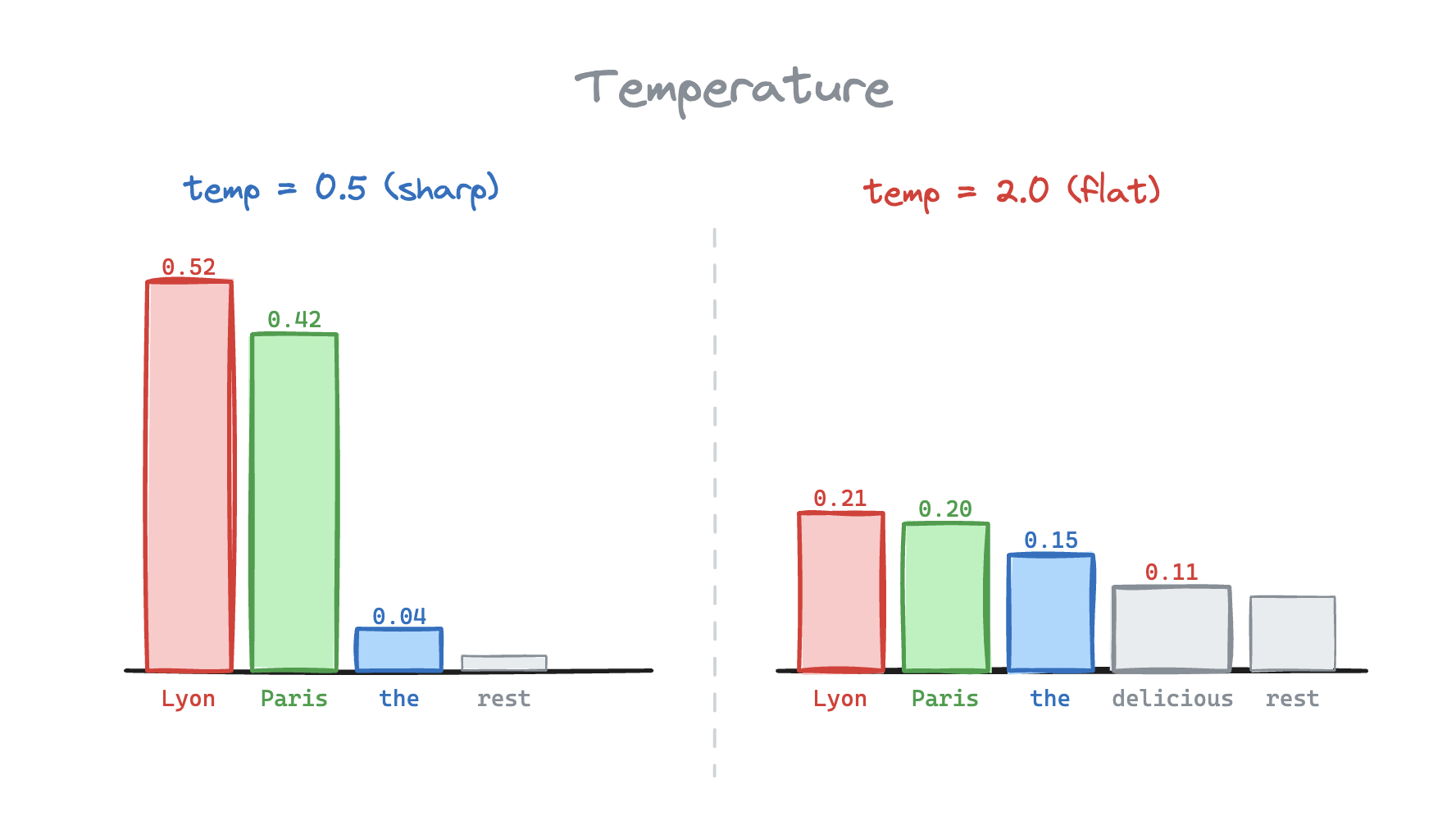
In our case, we would want to set a temperature to sharpen the distribution toward the most likely tokens {Lyon, Paris}.
What does changing actually look like?
Prompt: "The detective walked into the room and..."
| Temperature | Sentiment | Output |
|---|---|---|
| T = 0.2 | Predictable | "...immediately noticed the body on the floor. He pulled out his notebook and began to document the scene." |
| T = 0.7 | Sweet Spot | "...froze. Something was off... not the blood, not the furniture. The clock on the wall was still ticking." |
| T = 2.5 | Unpredictable | "...tasted the silence like a bad Tuesday. The lamp had apples. Somewhere, a fax machine." |
What if we just cut the tail out?
Great call. In ML terms, that's top-k and top-p sampling.
Top-k keeps the highest probability tokens and zeros out the rest. With , only Lyon and Paris survive.
Top-p, also known as nucleus sampling, is a bit smarter. Instead of a fixed count, you keep tokens until their cumulative probability crosses a threshold. So if we set :
Combining everything, sharpens the distribution, top-p=0.75 cuts the detail. This improves the chances of Paris getting picked by 1.5X, despite other noisy logits!
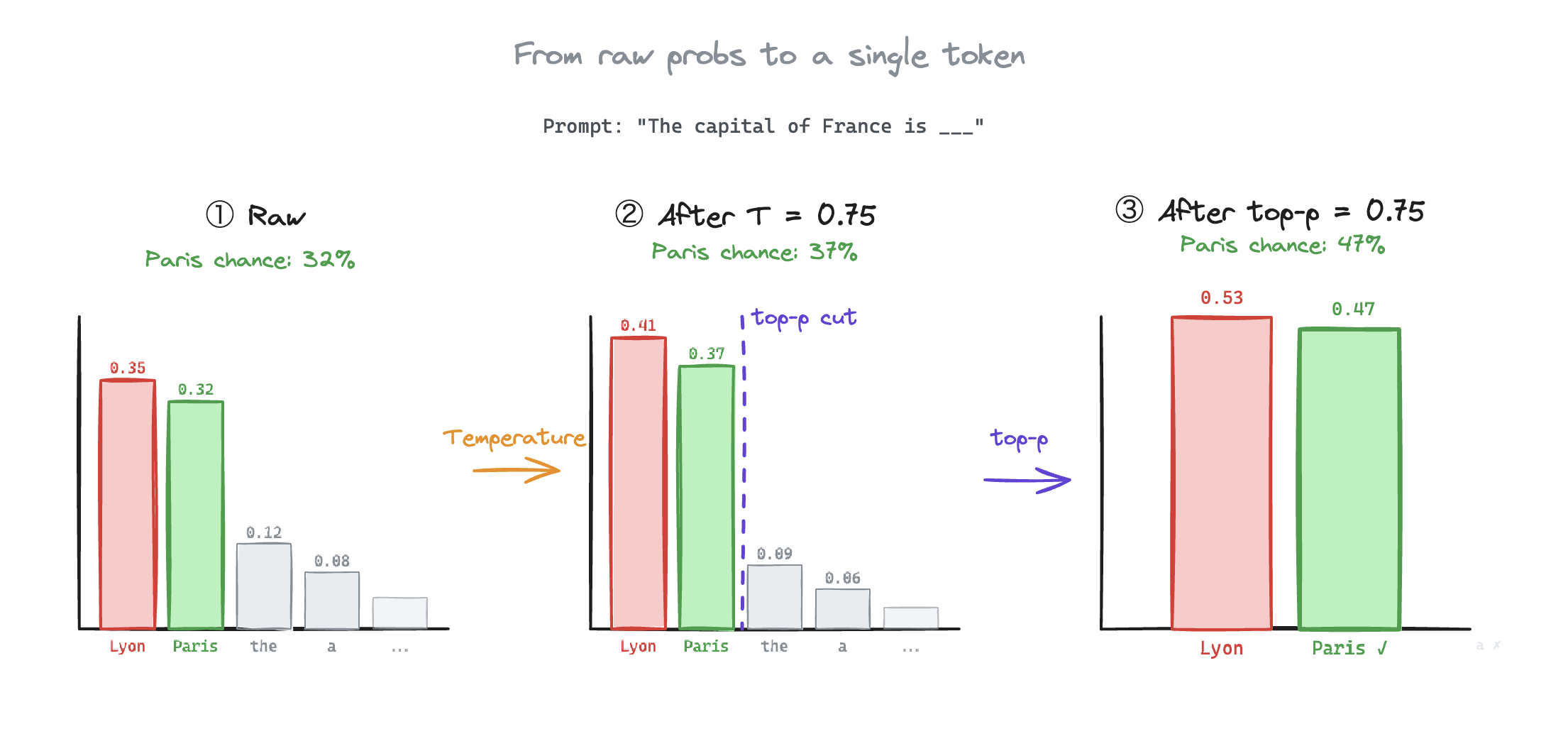
In practice, most hyperparameters are used to tune model output after training, based on the use case.
For example, Google Deepmind's AlphaCode skipped top-k and top-p sampling entirely. In their paper, they use a relatively high temperature to generate a diverse set of solutions for competitive programming questions, upon which a test suite filtered the bad ones out. This helped them beat majority of the human competitors on Codeforces.
That's why asking ChatGPT the same question twice doesn't give you the same output. Let's explore why this uncertainty makes it difficult to secure.
LLM Security
Traditionally, software has always been deterministic. Therefore, if you took the right counter measures you would always be reasonably secure against common hacking techniques. For example, parameterize your SQL queries and SQL injection is dead.
LLMs don't work that way. A jailbreak isn't an exploit in a traditional sense.
Jail · break: a prompt written to nudge the model's output outside its safety limits.
There's no clean fix for such attacks. You can train a smaller model to be a safety filter. But also, a safety filter on an LLM is more like a bouncer who sometimes lets things through if you ask nicely enough in French.
Training Data Extraction
Remember how lower temperature = more predictable? Turns out, "more predictable" also means "more likely to vomit out training data."
Carlini et al. prompted GPT-2 and got it to spit out memorized names, phone numbers, email addresses, and even 128-bit UUIDs. They compared perplexity across model sizes: if GPT-2 XL finds a sequence way more likely than GPT-2 Small, it's probably memorized.
The uncomfortable part is that they used greedy sampling to do it. At temperature 0, the model follows the highest-probability path every time, and memorized sequences sit right at the top.
Model Weight Extraction
Lets address the Large Language Model in the room. I apologize.
Training GPT-4 reportedly cost over $100 million. The problem is that many inference APIs let you request logits produced by the model.
By querying the same input with slight variations and recording the logit distributions, an attacker can mimic the model by training a "student" model. This process called model distillation.
Fortunately, the solution for this fix is pretty easy. OpenAI's API doesn't return all the logits. You can only query upto 20 logits out of several thousand produced by the model.
Prompt caching isolation
Most production inference servers cache the KV state of common prefixes. System prompts, shares instructions, boilerplates etc. This saves computing the KV Cache for boilerplate for every user.
In a poorly isolated system, an attacker can design a prompt that shares a prefix with a cached context. Since both requests point to the same KV block, the attackers attention runs against the shared content. This could expose the system prompt or reveal what prefixes other users are hitting.
This is commonly addressed by KV block ownership. Shared contexts go into shared blocks. The lookup key for a private block is a hash of the { token sequence, userID }. So even if two users send identical tokens, there isn't a key collision.
Even with these guardrails, there can be side-channel attacks such as analyzing Time-to-First-Token to expose hidden prefixes.
Key Takeaway
Every engineering optimization for LLM inference introduced a new interface that can be attacked. The tokenizer chunked your input in ways the model can't see. The KV cache traded isolation for efficiency.
None of these are bugs. They are the reason AI inference costs cents, and not dollars. But security is a different question that you can't put a cost against. That's what makes these problems hard to solve.
The End
You now understand the full cycle of events.

Next time ChatGPT pauses before responding, you'll know it's prefilling. When it streams fast then slows down, you'll know the KV cache is getting heavy. You have a hunch that every interface in this process is a potential attack surface. If the LLM gives you a confidently wrong answer, you'll know a high temperature let "Lyon" through.
This post is Part 3 of a 3-part series where I build an LLM inference engine from scratch in C++.
- ⭐ You're Billed by the Token. Here's What That Means.
- ⭐ Why Your First Token Is Always Late
- Sampling and LLM Security (you are here)
If you want to see the code of this without any fluff, WhiteLotus is the inference engine I built alongside this series. I hand wrote the code to make it more readable, while staying in line with production inference servers like vLLM.