- Published on
You're Billed by the Token. Here's What That Means.
- Authors

- Name
- Anirudh Sathiya Narayanan
One of the most popular benchmarks for early language models was the strawberry test.
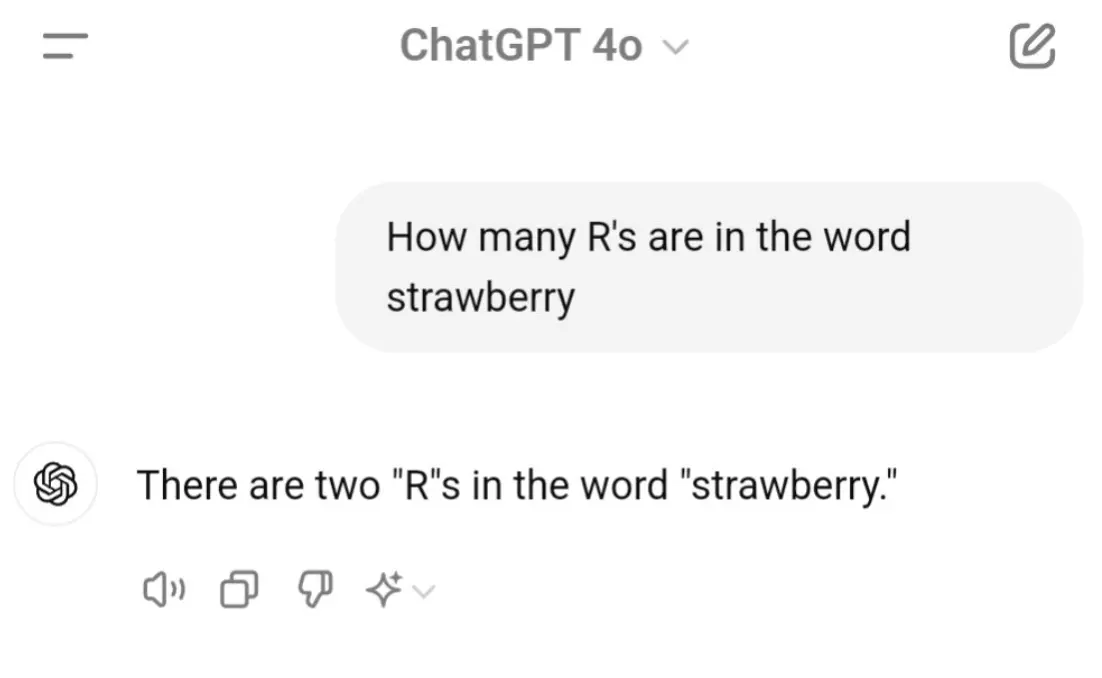
The tokenizer is why ChatGPT got it wrong.
When you send a message to ChatGPT, it needs to convert your text into a numerical format to process it.
Let's look at an example:


Notice how most words are one chunk by itself, but the first word is split into three parts?
Who decides this? Why can't we just use ASCII to represent the individual characters?
Cue the BPE Tokenizer.
What is a Tokenizer?
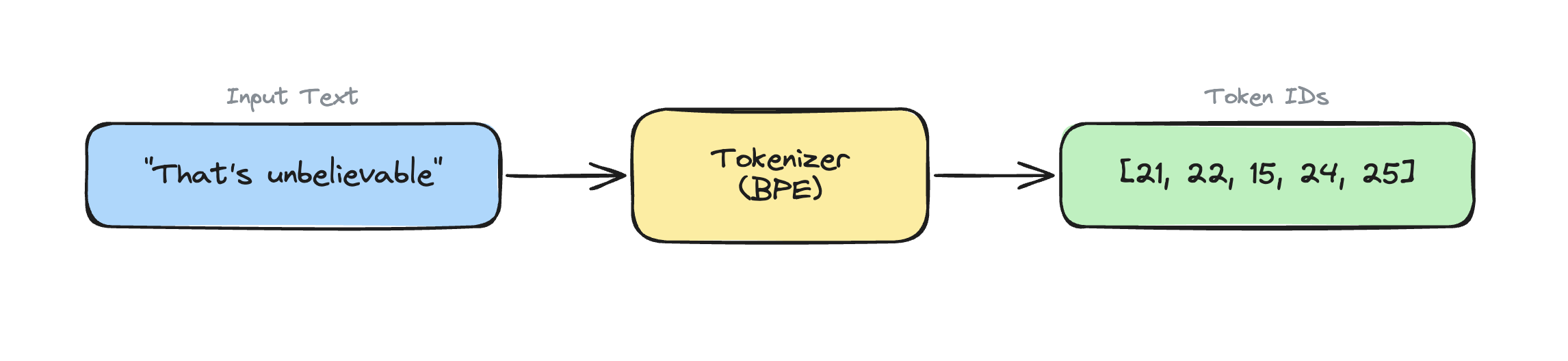
A tokenizer breaks text into chunks, and maps each chunk to a unique TokenId because neural networks only understand numbers.
The trick is to choose how to chunk: if we had a unique number for every word in the english dictionary, the vocabulary size explodes, and if we just map each letter to one of 26 tokenIds, then the resulting sequence of tokenIds becomes too long.
BPE: Step by Step
The two pre-requisites to BPE are:
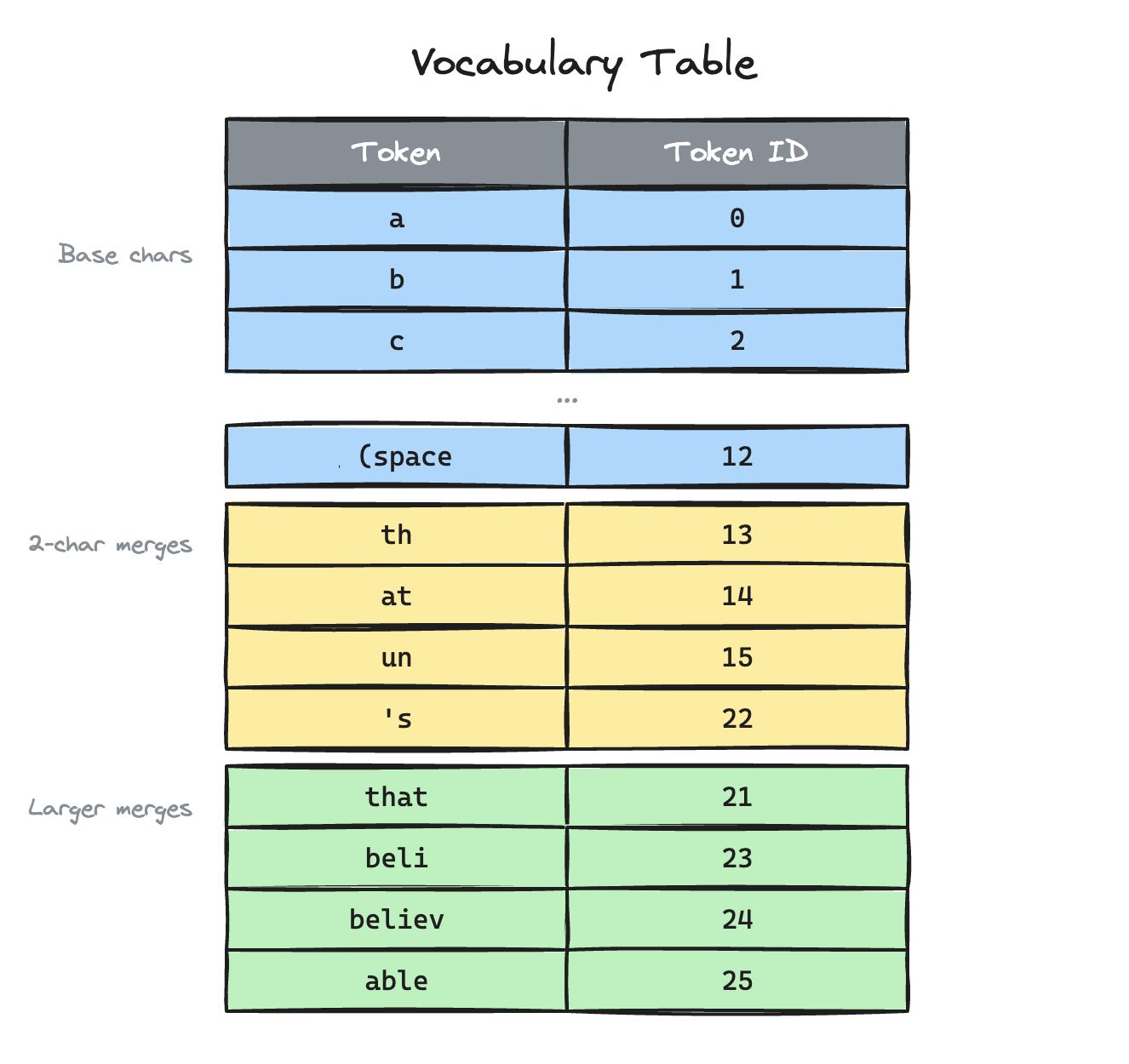
Vocabulary: a lookup table that maps every token to a unique integer. This is built during training.
This is what one might look like:
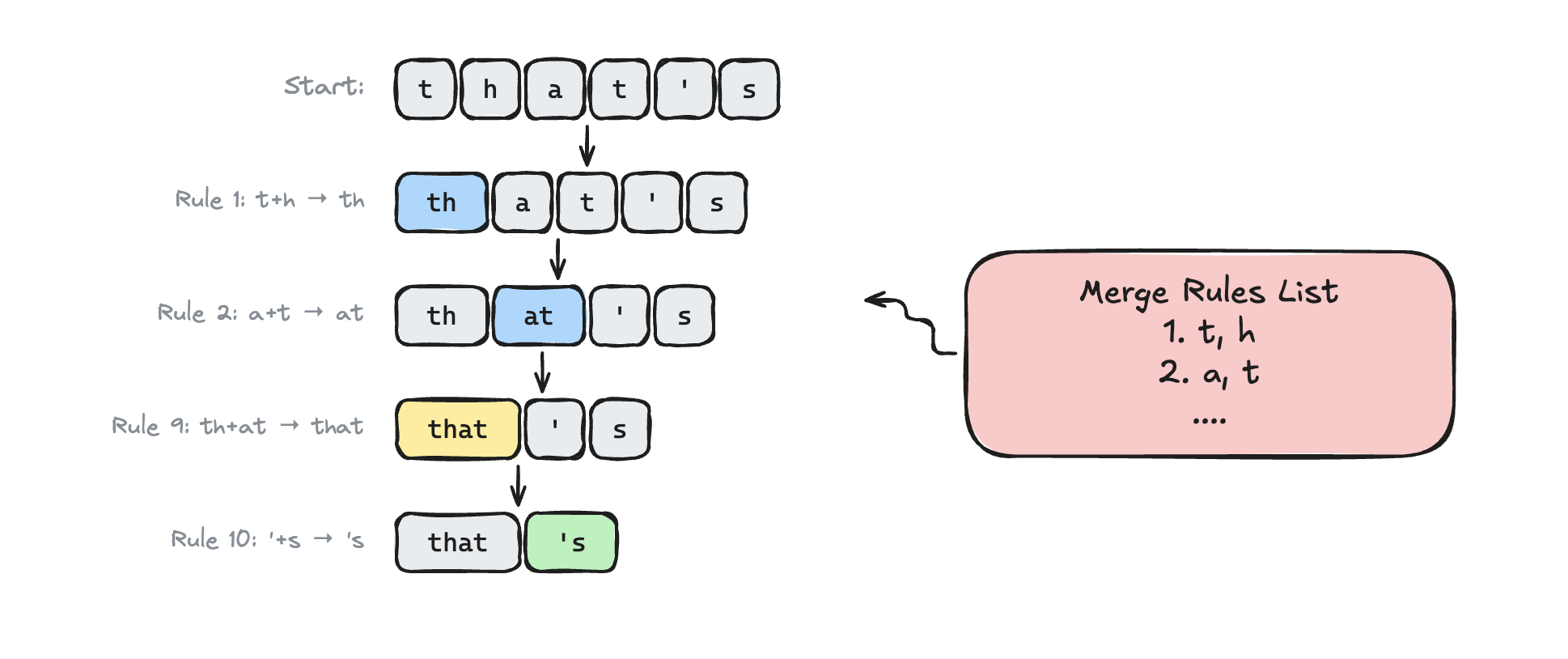
Merge list: an ordered list of pair merges, ranked by the order they were learned during training.
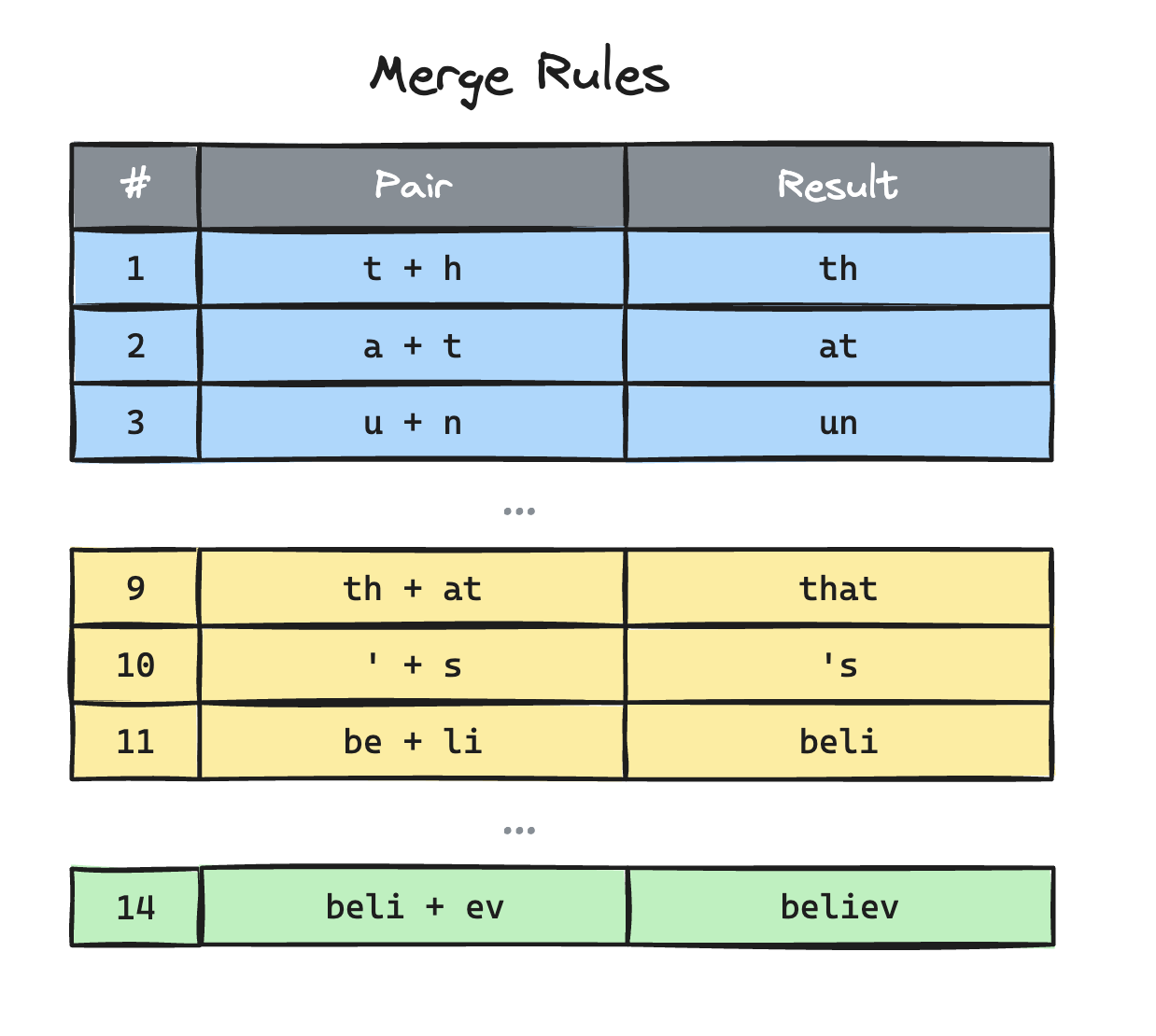
Tokenization:
Step 1: Break it into individual characters
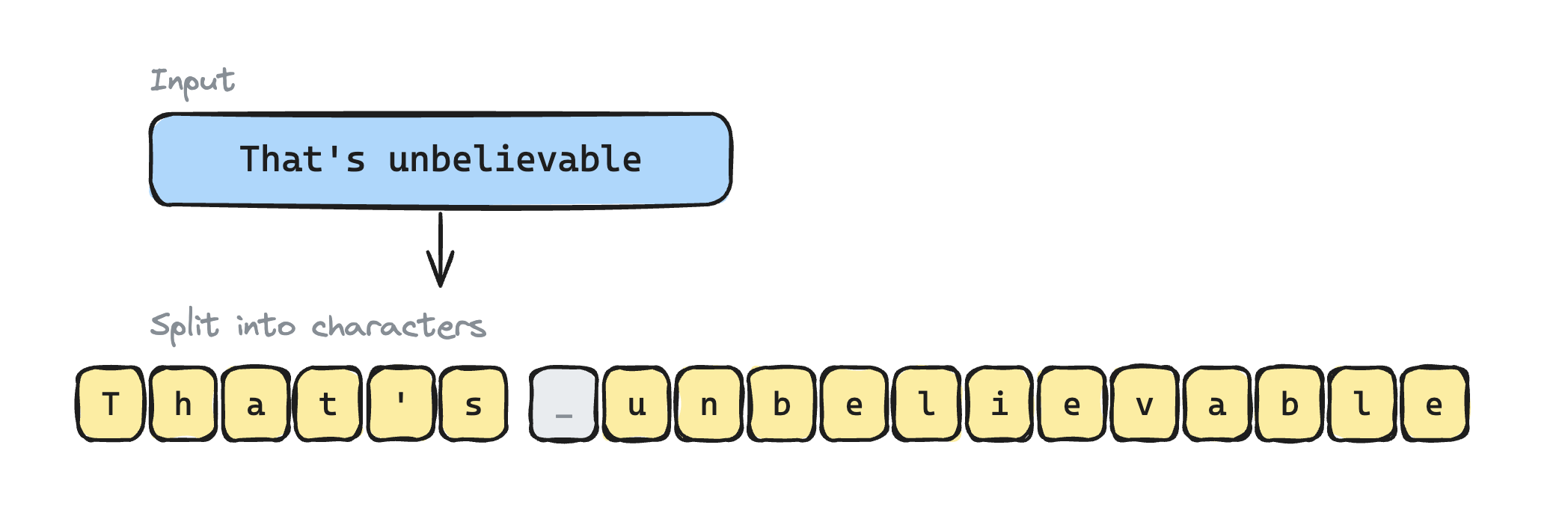
Step 2: Merge into chunks
We follow this algorithm to merge the letters into the largest possible chunks. Refer to the merge-rules list above.
for each merge rule (in priority order):
while the pair exists anywhere in the sequence:
replace all occurrences
Step 3: Convert the chunks into tokenIds
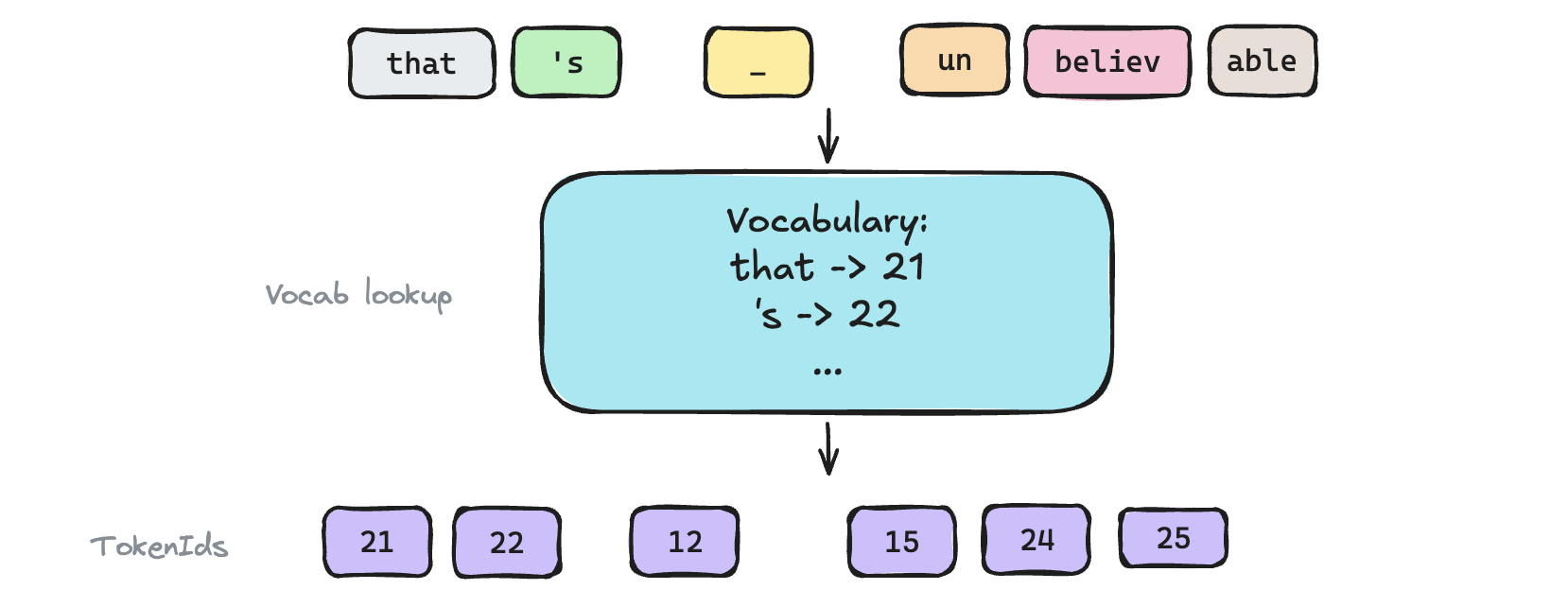
Voila! We have successfully converted "That's unbelievable" to [21, 22, 12, 15, 24, 25] tokenIds.
So "Why you pay for LLM usage by tokens" you ask?
Well that was a rhetorical question. If you said it's because it is the atomic unit of inference computation, you'd be absolutely right.
When the Tokenizer Goes Wrong
The tokenizer is a dumb preprocessor that runs before the model sees anything. Which means its mistakes are invisible to the model.
Math
Early GPT models were notoriously bad at arithmetic. Part of the blame lands here. For example, the decimal "3.141592" might get tokenized arbitrarily as [ "3.", "14", "159", "2" ]. The model only sees fragments of this broken down number.
How many r's in strawberry?
Three obviously. Duh. Unfortunately for early GPT3, converting text to tokenIds was also a lossy process. The newer models like OpenAI o1 fixed this by using techniques like chain of thought reasoning, which gave the model access to an internal "scratchpad" to process information and iron out the details.
Code
Since programming language is structured around defined syntax, general BPE tokenizers will most certainly fail at accurately representing code.
Production inference servers use a code specific tokenizer "trained" on existing code.
P.S. there's definitely atleast one mistake in the illustrations above but I promise I tried.
Appendix with more juicy information:
How is the tokenizer created?
The BPE algorithm is an epitome of beauty in simplicity. The training algorithm is the exact inverse of the encoding process.
- We look at the training corpus as a sequence of base tokens.
- We count adjacent pairs. For example, in "coconut" -> "co" would take precedence over "nu".
- Merge that pair ( 'c' + 'o' = "co" ) into a new token, add it to the vocabular, and append the merge rule to the bottom of the merge list.
- Repeat until you hit your target vocabulary size (e.g., 50,257 for GPT-2)
The merge list order is the frequency ranking from training. That's why the priority order matters at encode time.
Time and space complexity
Great! Now you're thinking like a systems level software engineer!!
Time complexity: O( n * m ) where n is the number of chars and m is the number of merge rules.
So its worth noting that GPT2's tokenizer uses a pre tokenization step. Refer to Appendix 2 (i had to put the more interesting appendices first sorry).
That being said, in practice the time complexity is a lot better since we're only iterating through each word and we often finish merging tokens within a word before iterating through the entire merge rules list.
Space complexity: Pretty trivial, but memory is becoming a bit expensive these days eh?
O(n) for the sequence itself, plus O(m) for the merge list and O(v) for the vocabulary table, where v is vocab size.
How do you tokenize the poop emoji 💩?
Characters depend on encoding (UTF8, UTF16) and you can't handle arbitrary unicode cleanly. By converting your text into bytes, you can treat every 256 bytes as one fundamental character and this can tokenize literally anything - broken text, code and any emoji you can think of 💅🏼.
BPE the best we have?
BPE is one of the more popular tokenizers, but there are others like WordPiece and Unigram used by other models. Wordpiece, primarily used by BERT models, constructs its merge list slightly differently: its not just "what paid appears most", but "what pair when merged best explains the corpus probabilistically". Unigram, which powers Llama, starts with a huge vocabulary of subwords and removes the ones that "hurts" the training data.
This post is Part 1 of a 3-part series where I build an LLM inference engine from scratch in C++.
- You're Billed by the Token. Here's What That Means. (you are here)
- ⭐ Why Your First Token Is Always Late
- ⭐ Sampling and LLM Security
The code for all of this lives in WhiteLotus on GitHub.